THE WORLD'S LARGEST AND MOST PROFITABLE COMPANIES
ARE DATA-DRIVEN.
BECOME A REAL-TIME DATA-DRIVEN COMPANY!
ARE DATA-DRIVEN.
BECOME A REAL-TIME DATA-DRIVEN COMPANY!
WHY ARE DATA ANALYTICS AND
MACHINE LEARNING IMPORTANT?
MACHINE LEARNING IMPORTANT?
Businesses are increasingly data-driven - capturing market and environmental data through analytics and machine learning to identify complex patterns, identify changes, and make predictions that directly impact performance. Managing a business through data-driven processes has become essential to staying at the forefront of the industry. Data-driven organizations need to manage a wide range of data.
WHY NOW?
The availability of open source software for big data analytics and machine learning, such as Hadoop, NumPy, Scikit Learning, Pandas, and Spark, have sparked the Big Data revolution. Large companies in huge industries such as retail, finance, healthcare and logistics have adopted data analytics to improve their competitiveness, responsiveness and efficiency. A few percent improvements could have a billion-dollar impact on their bottom line. Data analytics and machine learning are the largest HPC segment today.
THE CURRENT SITUATION
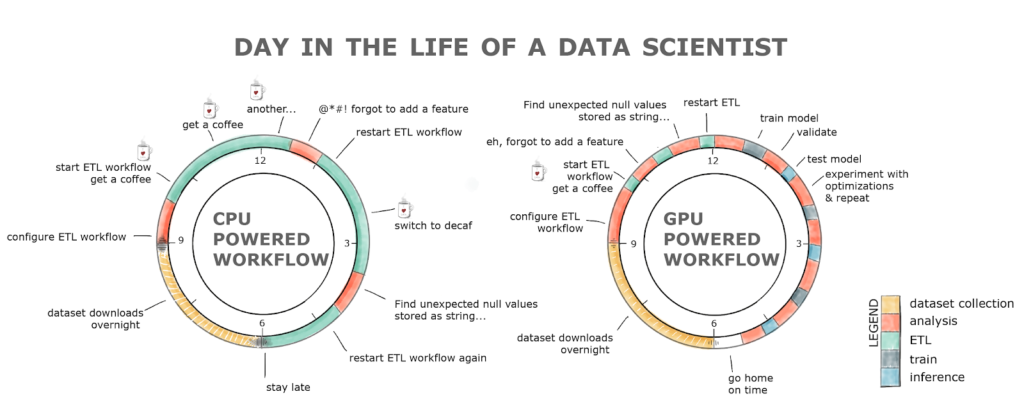
For companies that want to stay competitive, it's not easy to learn from ever-increasing amounts of data, manage the complexity of analytics, or keep up with siloed analytics solutions while operating on outdated infrastructure. What good is valuable data if data analysis takes far too long? Results made available quickly would have prevented loss of value, potential profits would have been achievable, fraud damage would have been prevented by faster responses.
WHAT IS THE REAL PROBLEM?
Today's data science problems require a dramatic increase in the volume of data
as well as the computing power required to process it.
WHAT IS THE PROBLEM RAPIDS SOLVES?
Don't take a child for a strongman's job, don't take a CPU for a fast GPU's job! While the amount of data in the world doubles every year, CPU computing has hit a wall with the end of Moore's Law. For the same reasons scientific computing and deep learning have turned to NVIDIA GPU acceleration, data analytics and machine learning where GPU acceleration is ideal.
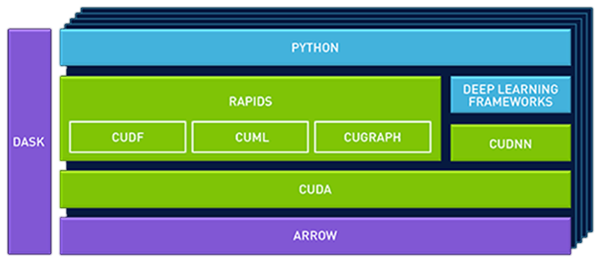
WHAT ARE RAPIDS?
RAPIDS is based on more than 15 years of NVIDIA® CUDA® development and machine learning experience. It is powerful new software for running end-to-end data science training pipelines entirely in the GPU, reducing training time from days to minutes.
NVIDIA has developed RAPIDS - an open source platform for accelerating data analytics and machine learning. RAPIDS is based on Python, has Pandas and Scikit-Learn-like interfaces, is built on the Apache Arrow in-memory data format, and can scale from 1 to multi-GPU to multiple nodes.
RAPIDS easily integrates with the world's most popular Python-based data science workflows. RAPIDS accelerate data science end-to-end - from data preparation to machine learning to deep learning. And through Arrow, Spark users can easily move data into the RAPIDS platform for acceleration.
IS THERE A SOLUTION THAT SIGNIFICANTLY SPEEDS UP PROCESSING?
Yes, now with NVIDIA's drive to advance GPU acceleration in machine learning and high-performance data analytics (ML/HPDA), the company reports that the RAPIDS platform with the XGBoost machine learning algorithm for training on an NVIDIA DGX-2 supercomputer delivers 50x speedup compared to CPU-only systems.
Thus, for data science, RAPIDS can reduce computation times from days to minutes.
THESE APPLICATIONS BENEFIT
FROM THE USE OF RAPIDS:
- Big data
- Forecasts, trends, predictions
- Pattern recognition
- Credit card recognition
- Risk Management
BEST USED WITH THESE FRAMEWORKS:

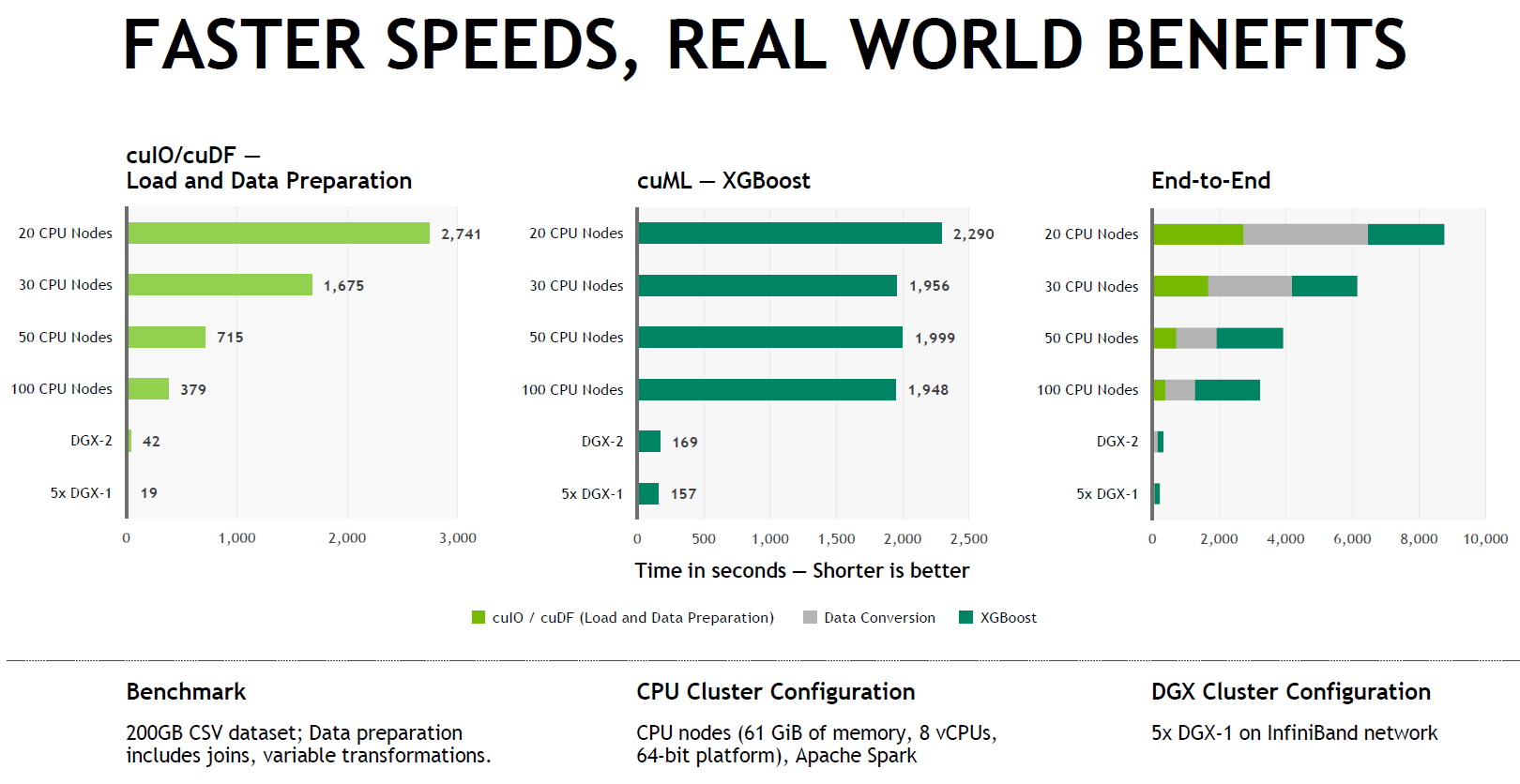
INCREASING DATA SCIENCE PERFORMANCE WITH RAPIDS
RAPIDS achieves speedup factors of 50x or more on typical end-to-end Data Science workflows.
RAPIDS leverages NVIDIA CUDA for high-performance GPU execution and makes this GPU parallelism and high memory bandwidth accessible via easy-to-use Python interfaces. RAPIDS focuses on common data preparation tasks for analytics and data science and provides a powerful and familiar Data Frame API.
This API integrates with a wide range of machine learning algorithms without typical serialization costs, enabling end-to-end pipeline acceleration. RAPIDS also provides support for multi-node and multi-GPU implementations, enabling scaling to much larger datasets.
The RAPIDS container contains a notebook and code demonstrating a typical end-to-end ETL and ML workflow.
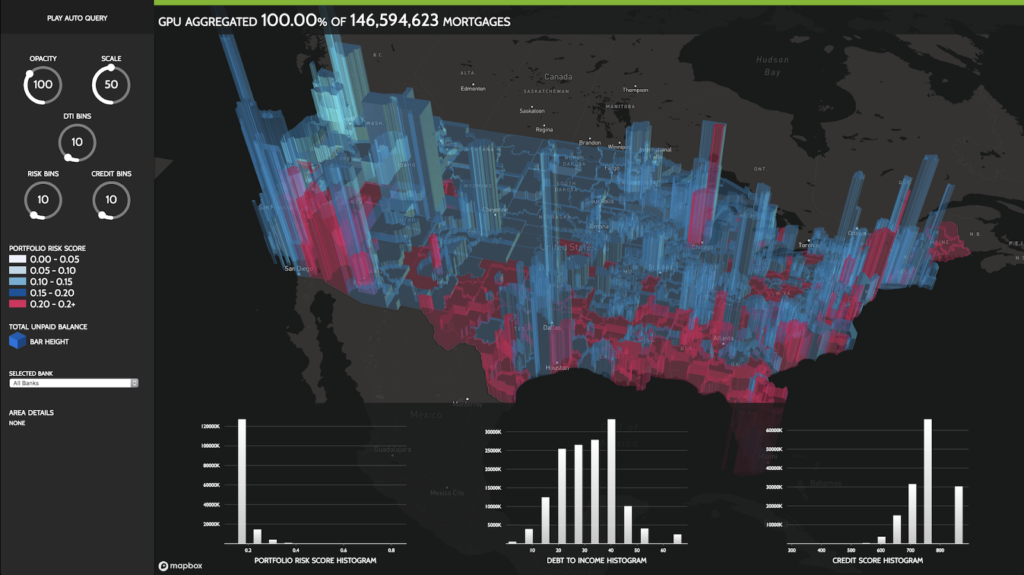
The example trains a home loan risk assessment model using all loan data for the years 2000 to 2016 in the Fannie Mae Loan Performance Dataset, consisting of approximately 400 GB of data in memory.
The following figure shows the geographic visualization
The example loads the data into GPU memory using the RAPIDS CSV reader. The ETL in this example performs a number of operations, including extracting months and years from datetime fields, joins of multiple columns between DataFrames, and groupby aggregations for feature engineering. The resulting feature data is then converted and used to train a gradient-boosted decision tree model on the GPU using XGBoost.
This workflow runs end-to-end on a single NVIDIA DGX-2 server with 16x Tesla V100 GPUs, 10x faster than 100 AWS r4.2xLarge instances, as shown in the following diagram. Comparing GPU performance to CPU performance one-to-one, this equates to a speedup of well over 50x
GPU APPROACH
One of the biggest competitive advantages NVIDIA enjoys in this space is a huge ecosystem built around CUDA. Hardware vendors support NVIDIA GPUs, while software vendors and the open source communities support NVIDIA CUDA and the GPUs based on it. As a result, the company has a significant lead in the deep learning training and inferencing market and is extending that lead with RAPIDS. As mentioned earlier, the far too long runtimes for previous data analytics can be drastically shortened by using GPU processors. RAPIDS enables the use of lightning-fast GPU processors instead of slow x86 processors, with the latter still responsible for general operating system tasks.
RECOMMENDED HARDWARE
RAPIDS RECOMMENDED CONFIGURATIONS
RAPIDS Deployment Phase | Recommended GPU configuration | Minimum CPU cores | Minimum main memory | Boot drive | Local data storage | Networking connection |
|---|---|---|---|---|---|---|
Development | 2 x Quadro GV100 & NVLINK | 10 | 128 GB | 500GB SSD | 2TB SSD | 1GbE / 10GbE |
Development & Production | 4x V100 & NVLINK | 20 | 256 GB | 500GB SSD | 4TB SSD | 1GbE / 10GbE |
Production | 4x V100 SXM2 & NVLINK | 20 | 256 GB | 500GB SSD | 4TB SSD | 10GbE / 100GbE/IB |
Production | 8x V100 SXM2 & NVLINK | 40 | 512 GB | 500GB SSD | 4TB SSD / NVMe | 10GbE / 100GbE/IB |
Production | 16x V100 SXM3 & NVSWITCH | 56 | 1 TB | 500GB SSD | 10TB SSD / NVMe | 40GbE / 100GbE/IB |
DEVELOPMENT SYSTEMS
As development systems sysGen offers you the devCube as a development system. The devCube is a well-tested and proven system that is used by many of our customers for deep learning tasks.
PRODUCTION SYSTEMS
Productive servers are dedicated to the high demands of continuous operation and constant workload. Redundant power supplies and enterprise-class components are part of our service.
System model | CPU | RAM | Memory (OS) | Memory (data) | Graphics cards | Networking connection | Freely configurable? |
|---|---|---|---|---|---|---|---|
| NVIDIA DGX-1 | 2x Intel Xeon E5.2698 v4 | 512GB DDR4 ECC reg | 480GB SATA SSD | 4x 1.92TB SATA SSD (RAID0) | 8x NVIDIA Tesla V100 NVLink | 2x 10 Gigabit LAN, 4x Infiniband EDR 100 Gbit/s | No |
| NVIDIA DGX-2 | 2x Intel Xeon Platinum 8168 | 1.5TB DDR4 ECC reg | 2x 960GB NVME SSD | 8x 3.84TB NVME SSDs | 16x NVIDIA Tesla V100 NVLink | 2x 10/25 Gigabit Ethernet, 8x Infiniband/Ethernet EDR 100 Gbit/s | No |
OPTIMIZED SOFTWARE STACK
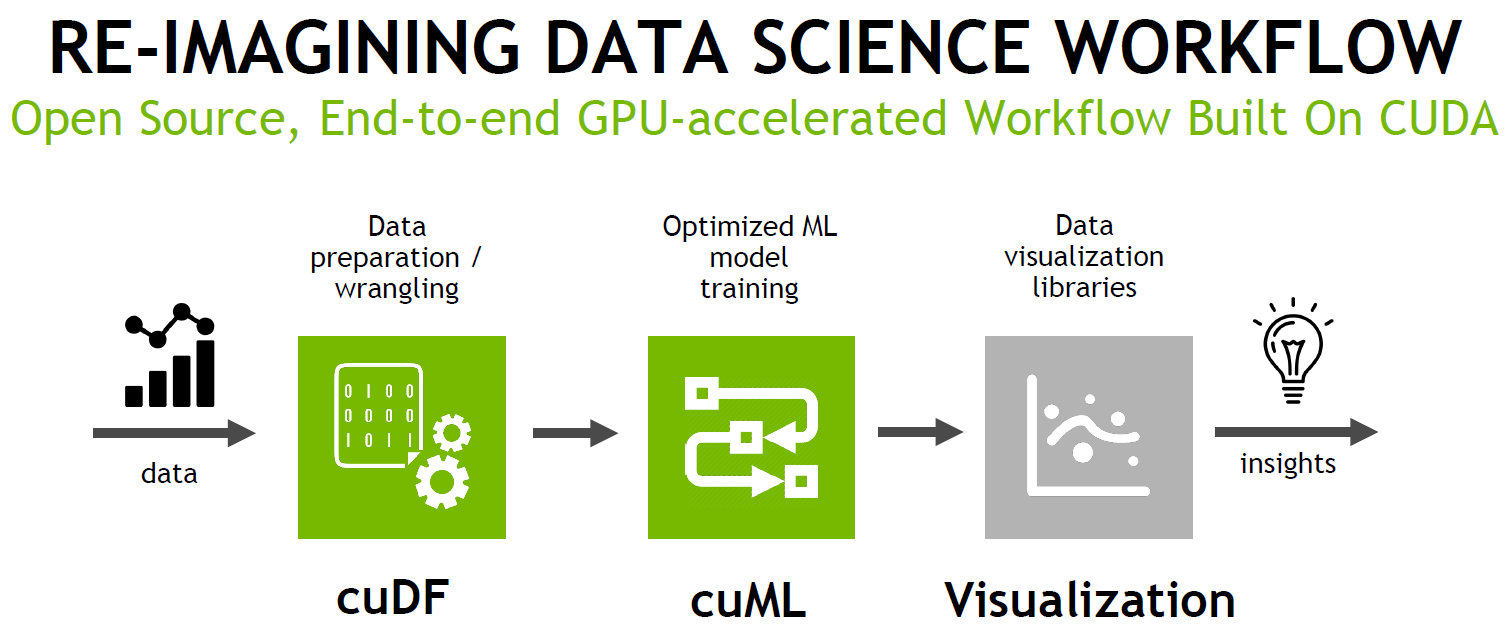
NVIDIA RAPIDS contains CUDF, CUML and CUGRAPH as core tools. With cuDF you can prepare and prepare your raw data. Then, cuML uses an optimized machine learning model training algorithm to process the prepared data. Afterwards, your data is visualized and displayed to you.
APACHE ARROW
Apache Arrow is a columnar in-memory data structure that provides efficient and fast data exchange with flexibility to support complex data models.
CUDF
The RAPIDS cuDF library is an Apache Arrow-based DataFrame manipulation library that accelerates data loading, filtering, and manipulation for model training data preparation. The Python bindings of the core-accelerated CUDA DataFrame manipulation primitives mirror the Pandas interface for seamless onboarding of Pandas users.
CUML
RAPIDS cuML is a collection of GPU-accelerated machine learning libraries that will provide GPU versions of all machine learning algorithms available in scikit-learn.
CUGRAPH
This is a framework and collection of graph analytics libraries that integrate seamlessly with the RAPIDS Data Science Platform.
DEEP LEARNING LIBRARIES
RAPIDS provides native array_interface support. This means that data stored in Apache Arrow can be seamlessly passed to deep learning frameworks with array_interface such as PyTorch and Chainer.
VISUALIZATION LIBRARIES IN BRIEF
RAPIDS will include tightly integrated data visualization libraries based on Apache Arrow. The native GPU in-memory data format provides high performance data visualization with high FPS, even for very large data sets.
This info is based on accessible information from NVIDIA
INTRODUCTION OF RAPIDS
At the GPU Technology Conference in Munich, graphics card manufacturer Nvidia presented the Rapids open source platform. It is primarily aimed at users from the fields of data science and machine learning and represents a collection of libraries that are intended to enable GPU-accelerated data analysis. In addition to Nvidia, companies such as IBM, HPE, Oracle and Databricks have also announced their support for the project.
As the graphics card manufacturer explains, Rapids is based on Cuda, the in-house platform for parallel programming. The new platform is designed to enable developers to create end-to-end pipelines for data analysis. Nvidia has achieved up to 50 times faster results on the DGX-2 supercomputer compared to systems that rely only on CPUs. The platform is built on well-known open source projects such as Apache Arrow, pandas and scikit-learn, and is said to bring GPU acceleration to popular Python toolchains. Integration with Apache Spark is also planned.
NVIDIA has been working with members of the Python community to create Rapids for two years. Currently, the collection consists of a Python GPU DataFrame library, a C GPU DataFrame library and alpha versions of a cuML and cuDF library. According to NVIDIA founder Jensen Huang, the overall package is intended to advance work in data analytics and machine learning.
The entire Rapids project can be found on GitHub. More information, including installation instructions, can be found on the official website. Companies like Walmart are already using the new platform.