Questions about your request or an order? Contact us
Systeme und Informatikanwendungen Nikisch GmbHsysGen GmbH - Am Hallacker 48 - 28327 Bremen - info@sysgen.de
Questions about your request or an order? Contact us
Cookie preferences
This website uses cookies, which are necessary for the technical operation of the website and are always set. Other cookies, which increase the comfort when using this website, are used for direct advertising or to facilitate interaction with other websites and social networks, are only set with your consent.
Configuration
Technically required
These cookies are necessary for the basic functions of the shop.
"Allow all cookies" cookie
"Decline all cookies" cookie
CSRF token
Cookie preferences
Currency change
Customer recognition
Customer-specific caching
Individual prices
Selected shop
Session
Comfort functions
These cookies are used to make the shopping experience even more appealing, for example for the recognition of the visitor.
Run complete data science workflows with high-speed GPU computing power and parallelize data loading, data manipulation, and machine learning for 50x faster end-to-end data science pipelines.
WHY RAPIDS?
Today, data science and machine learning have become the world's largest compute segment. Minor improvements in the accuracy of analytic models mean billions in profits for the enterprise. To build the best models, data scientists must painstakingly train, evaluate, iterate, and re-train to produce highly accurate results and powerful models. With RAPIDS™, processes that used to take days now take minutes, making it easier and faster to create and deploy value-added models.
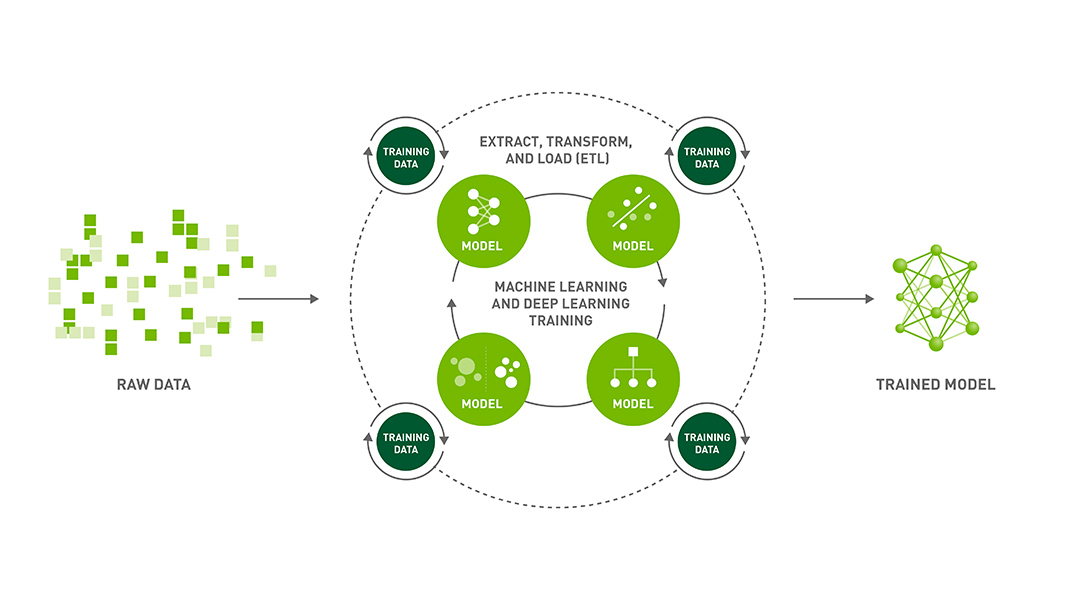
Workflows have many iterations of converting raw data into training data that is fed into many algorithm combinations ,which are subjected to hyperparameter tuning to find the right combinations of models, model parameters, and data features for optimal accuracy and performance.
BUILDING A POWERFUL ECOSYSTEM
RAPIDS is a suite of open source software libraries and APIs for running data science pipelines entirely on GPUs - and can reduce training times from days to minutes. RAPIDS is built on NVIDIA® CUDA-X AI™ and combines years of development in graphics, machine learning, deep learning, high-performance computing (HPC) and more.
Shorter processing times
Data science is all about accelerating results. RAPIDS leverages NVIDIA CUDA®. This allows you to accelerate your workflows by running the entire data science training pipeline on GPUs. This reduces training time and model deployment frequency from days to minutes.
Use the same tools
By hiding the complexity of GPU work and even communication protocols behind the scenes within data centers, RAPIDS creates an easy way to do data science. As more data scientists use Python and other high-level languages, providing acceleration without code switching is essential to rapidly improve development time.
Execute scaled everywhere
RAPIDS can run anywhere - in the cloud or on-premises. You can easily scale from a workstation to servers with multiple GPUs and deploy it in production with Dask, Spark, MLFlow, and Kubernetes.
Data science fit for business
Access to reliable support is often essential for organizations that use data science for business-critical insights. NVIDIA Enterprise Support is available globally with NVIDIA AI Enterprise, an end-to-end AI software suite, and includes guaranteed response times, priority security notifications, regular updates, and contact with NVIDIA AI experts.
LIGHTNING FAST PERFORMANCE WITH BIG DATA
The results show that GPUs offer dramatic cost and time savings for small and large Big Data analytics problems. Using familiar APIs such as Pandas and Dask, RAPIDS is up to 20 times faster than the best CPU baseline at 10 terabytes on GPUs. With just 16 NVIDIA DGX A100s, it achieves the performance of 350 CPU-based servers. This makes the NVIDIA solution 7x more cost-effective while delivering HPC-level performance.
FASTER DATA ACCESS, LESS DATA MOVEMENT
Common data processing tasks have many steps (data pipelines) that Hadoop cannot process efficiently. Apache Spark solved this problem by keeping all data in system memory, which allowed for more flexible and complex data pipelines, but introduced new bottlenecks. Analyzing even a few hundred gigabytes (GB) of data could take hours, if not days, on Spark clusters with hundreds of CPU nodes. To realize the true potential of Data Science, GPUs must be at the center of the data center design, which consists of these five elements: compute, network, storage, provisioning and software. In general, end-to-end Data Science workflows are 10 times faster on GPUs than on CPUs.
DEVELOPMENT OF DATA PROCESSING
RAPIDS versatile
RAPIDS provides a foundation for a new high-performance data science ecosystem and lowers the barrier to entry for new libraries through interoperability. Integration with leading data science frameworks such as Apache Spark, cuPY, Dask, and Numba, as well as numerous deep learning frameworks such as PyTorch, TensorFlow, and Apache MxNet, helps broaden adoption and foster integration with others.
dask-sql is a distributed SQL engine in Python that performs ETL at scale with RAPIDS for GPU acceleration.
Based on RAPIDS, NVTabular accelerates feature engineering and preprocessing for recommender systems on GPUs.
Based on Streamz and RAPIDS and written in Python, cuStreamz accelerates streaming data processing to GPUs.
Integrated with RAPIDS, Pender dash enables real-time interactive visual analysis of multi-gigabyte datasets even on a single GPU.
The RAPIDS Accelerator for Apache Spark provides a set of plug-ins for Apache Spark that leverage GPUs to accelerate processing via RAPIDS and UCX software.
TECHNOLOGY AT THE HEART
RAPIDS is based on CUDA primitives for low-level compute optimization, but makes GPU parallelism and high memory bandwidth accessible via easy-to-use Python interfaces. RAPIDS supports end-to-end data science workflows, from data loading and preprocessing to machine learning, graph analysis, and visualization. It is a full-featured Python stack that scales for enterprise Big Data use cases.
DATA LOADING AND PREPARATION
RAPIDS' data loading, pre-processing, and ETL functions rely on Apache Arrow to load, join, aggregate, filter, and otherwise manipulate data, all in a Pandas-like API familiar to data scientists. Users can expect typical speed increases of 10x or more.
RAPIDS' machine learning algorithms and mathematical primitives follow a familiar Scikit-Learn-like API. Popular tools such as XGBoost, Random Forest, and many others are supported for both single-GPU and large datacenter implementations. For large datasets, these GPU-based implementations can complete 10-50x faster than their CPU equivalents.
RAPIDS graph algorithms like PageRank and features like NetworkX efficiently leverage the massive parallelism of GPUs to accelerate large graph analysis by over 1000x. Explore up to 200 million edges on a single NVIDIA A100 Tensor Core GPU and scale to billions of edges on NVIDIA DGX™ A100 clusters.
RAPIDS' visualization capabilities support GPU-accelerated cross-filtering. Inspired by the JavaScript version of the original, it enables interactive and super-fast multi-dimensional filtering of over 100 million rows of tabular data sets.
While Deep Learning is effective in areas such as computer vision, natural language processing, and recommender systems, there are areas where its use is not mainstream. For problems involving tabular data consisting of columns of categorical and continuous variables, techniques such as XGBoost, gradient boosting, or linear models are commonly used. RAPIDS streamlines the preprocessing of tabular data on GPUs and provides seamless handoff of data directly to all frameworks that support DLPack, such as PyTorch, TensorFlow, and MxNet. These integrations open up new possibilities for creating rich workflows, including those that were previously out of the question, such as feeding new features created by deep learning frameworks back into machine learning algorithms.
MODERN DATA CENTERS FOR DATA SCIENCE
There are five key ingredients to building AI-optimized data centers in the enterprise. Key to the design is the placement of GPUs in the center.
Compute
With their massive compute power, systems with NVIDIA GPUs are the central compute building block for AI data centers. NVIDIA DGX systems deliver breakthrough AI performance and can replace an average of 50 dual-socket CPU servers. This is the first step in giving data scientists the industry's most powerful tools for data exploration.
Software
By hiding the complexity of working with the GPU and communication protocols behind the scenes within the data center architecture, RAPIDS creates an easy way to do data science. As more data scientists use Python and other high-level languages, providing acceleration without code change is critical to rapidly improving development time.
Networking
Remote Direct Memory Access (RDMA) in NVIDIA Mellanox® network interface card controllers (NICs), NCCL2 (NVIDIA collective communication library), and OpenUCX (an open source framework for point-to-point communication) has led to tremendous improvements in training speed. With RDMA, GPUs can communicate directly across nodes at up to 100 gigabits per second (Gb/s), allowing them to span multiple nodes and operate as if they were on a single large server.
APPLICATION AREA
Enterprises are turning to Kubernetes and Docker containers for large-scale pipeline deployments. Combining containerized applications with Kubernetes allows enterprises to reprioritize which task is most important and gives AI data centers more resilience, reliability, and scalability.
Storage
GPUDirect® Storage enables both NVMe and NVMe over Fabric (NVMe-oF) to read and write data directly to the GPU, bypassing the CPU and system memory. This frees up the CPU and system memory for other tasks, while giving each GPU access to an order of magnitude more data with up to 50 percent more bandwidth.
Without computing power, data scientists had to "dumb down" their algorithms to run fast enough. that's over now: GPUs allow us to do the previously impossible.
Bill Groves, Chief Data Officer, Walmart
NASA's global models generate terabytes of data. Before RAPIDS, a button was pressed and six or seven hours were spent waiting for the results. Speeding up the training cycle was a completely new approach to model development.
Dr. John Keller, NASA Goddard Space Flight Center
With a 100-fold improvement in training times and a 98 percent cost savings, Capital One sees RAPIDS.ai and Dask as the next big breakthrough for data science and machine learning.
Mike McCarty, Director of Software Engineering, Capital One Center for Machine Learning
This website uses cookies, which are necessary for the technical operation of the website and are always set. Other cookies, which increase the usability of this website, serve for direct advertising or simplify interaction with other websites and social networks, will only be used with your consent.