Questions about your request or an order? Contact us
Systeme und Informatikanwendungen Nikisch GmbHsysGen GmbH - Am Hallacker 48 - 28327 Bremen - info@sysgen.de
Questions about your request or an order? Contact us
Cookie preferences
This website uses cookies, which are necessary for the technical operation of the website and are always set. Other cookies, which increase the comfort when using this website, are used for direct advertising or to facilitate interaction with other websites and social networks, are only set with your consent.
Configuration
Technically required
These cookies are necessary for the basic functions of the shop.
"Allow all cookies" cookie
"Decline all cookies" cookie
CSRF token
Cookie preferences
Currency change
Customer recognition
Customer-specific caching
Individual prices
Selected shop
Session
Comfort functions
These cookies are used to make the shopping experience even more appealing, for example for the recognition of the visitor.
Multi-Instance GPU(MIG) extends the performance and value of every NVIDIA H100, A100 and A30 Graphics processor. MIG can partition the A100 GPU into up to seven instances, each fully isolated and with its own high-bandwidth memory, cache, and compute cores. Now administrators can support any workload, from the smallest to the largest, and right-size a GPU for each job with guaranteed quality of service (QoS). It can also optimize workloads and extend the reach of accelerated compute resources to every user.
PERFORMANCE OVERVIEW
EXTENSION OF ACCESS TO GPUS for MORE USERS
With MIG, you can achieve up to 7x more GPU resources on a single A100 GPU. MIG gives researchers and developers more resources and flexibility than ever before.
OPTIMIZE GPU UTILIZATION
MIG provides the flexibility to select many different instance sizes, enabling the deployment of right-sized GPU instances for each workload, ultimately resulting in optimal utilization and maximization of data center investments.
enable EXecution oF mIXed workloads
MIG enables simultaneous execution of inference, training, and high-performance computing (HPC) workloads on a single GPU with deterministic latency and throughput.
HOW THE TECHNOLOGY WORKS
Without MIG, different tasks like AI inference queries running on the same GPU compete for the same resources (e.g. memory bandwidth). A task that consumes more memory bandwidth starves others, causing multiple tasks to miss their latency targets. With MIG, tasks run concurrently on different instances, each with dedicated compute, memory, and memory bandwidth resources, resulting in predictable performance with high quality of service and maximized GPU utilization.
ACHIEVING ULTIMATE FLEXIBILITY IN THE DATA CENTER
An NVIDIA A100 GPU can be partitioned into MIG instances of different sizes. For example, an administrator could create two instances with 20 gigabytes (GB) of memory each, or three instances with 10 GB, or seven instances with 5 GB, or a mixture of both. This allows the system administrator to provide GPUs of the right size to users for different types of workloads.
MIG instances can also be dynamically reconfigured, allowing administrators to shift GPU resources base on changing user and business needs. For example, seven MIG instances can be used for low-throughput conferencing during the day and reconfigured into one large MIG instance for deep learning training at night.
EXCEPTIONAL QUALITY OF SERVICE
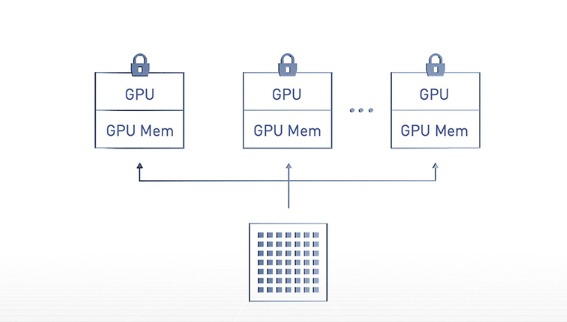
Each MIG instance has a dedicated set of hardware resources for data processing, memory and cache that provide guaranteed quality of service (QoS) and fault isolation for the workload. This means that a fault in an application running on one instance will not affect applications running on other instances. In addition, different types of workloads can run on different instances: interactive model development, deep learning training, AI inference, or HPC applications. Since the instances run in parallel, the workloads also run in parallel, but separately and isolated on the same physical A100 GPU.
MIG is ideal for workloads such as low-latency AI model development and inferencing. These workloads can take full advantage of the A100's features and fit into the memory allocated to each instance.
MIG in NVIDIA H100
Based on NVIDIA Hopper™ architecture, the H100 extends MIG by supporting multi-tenant, multi-user configurations in virtualized environments for up to seven GPU instances, with each instance securely isolated at the hardware and hypervisor level through Confidential Computing. Dedicated video decoders for each MIG instance enable high-throughput intelligent video analytics (IVA) on shared infrastructure. Hopper's concurrent MIG profiling allows administrators to monitor correctly sized GPU acceleration and allocate resources for multiple users.
Researchers with smaller workloads can use MIG instead of a full cloud instance to securely isolate a portion of a GPU, confident that their data is protected during storage, transfer and use. This increases the flexibility for cloud service providers to serve smaller potential customers and be more cost effective.
SEE MIG IN ACTION
BUILT FOR IT AND DEVOPS
MIG enables fine-grained GPU provisioning by IT and DevOps teams. Each MIG instance behaves like a standalone GPU for applications, eliminating the need to make changes to the CUDA® platform. MIG can be deployed in all major enterprise computing environments.
7 x 10 GB 4 x 20 GB 2 x 40 GB (more computing capacity) 1 x 80 GB
7 x 10 GB 3 x 20 GB 2 x 40 GB 1 x 80 GB
GPU profiling and monitoring
Simultaneously on all instances
Only one instance at a time
Secure clients
7x
1x
Media decoder
Dedicated NVJPEG and NVDEC per instance
Limited options
Preliminary specifications, subject to change
This website uses cookies, which are necessary for the technical operation of the website and are always set. Other cookies, which increase the usability of this website, serve for direct advertising or simplify interaction with other websites and social networks, will only be used with your consent.