Questions about your request or an order? Contact us
Systeme und Informatikanwendungen Nikisch GmbHsysGen GmbH - Am Hallacker 48 - 28327 Bremen - info@sysgen.de
Questions about your request or an order? Contact us
Cookie preferences
This website uses cookies, which are necessary for the technical operation of the website and are always set. Other cookies, which increase the comfort when using this website, are used for direct advertising or to facilitate interaction with other websites and social networks, are only set with your consent.
Configuration
Technically required
These cookies are necessary for the basic functions of the shop.
"Allow all cookies" cookie
"Decline all cookies" cookie
CSRF token
Cookie preferences
Currency change
Customer recognition
Customer-specific caching
Individual prices
Selected shop
Session
Comfort functions
These cookies are used to make the shopping experience even more appealing, for example for the recognition of the visitor.
BeeGFS is a hardware-independent POSIX parallel file system (also known as software-defined parallel storage) developed with a strong focus on performance and designed for ease of use, installation and management. BeeGFS is built on an available-source development model (source code is publicly available) and offers a self-supported Community Edition and a fully supported Enterprise Edition with additional features and functionality. BeeGFS is designed for all performance-oriented environments, including HPC, AI and Deep Learning, Life Sciences and Oil & Gas (to name a few).
BeeGFS works with lightweight, high performance service daemon(s) in user space over the arbitrated filesystem, such as ext4, xfs, zfs, Hadoop. This allows users to free up maximum bandwidth, enable higher performance of the hardware and increase network pipe speeds to applications. BeeGFS native client and server components are available for Linux on x86, x86_64, AMD, ARM & OpenPower or any other CPU architecture.
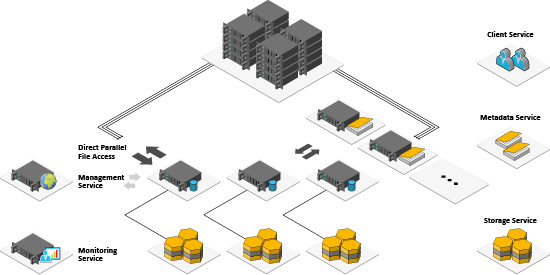
BeeGFS's unique userspace architecture concept makes it possible to minimize the latency of accessing the metadata (e.g. during directory lookups) and distributes the metadata across multiple servers so that each of the metadata servers stores a portion of the global file system namespace.
By increasing the number of servers and disks in the system, it is possible to scale the performance and capacity of the file system to the level you need, seamlessly from small clusters to enterprise-class systems with thousands of nodes.
BeeGFS transparently distributes user data across multiple servers. By increasing the number of servers and disks in the system, you can easily scale the performance and capacity of the file system to the level you need, seamlessly from small clusters to enterprise-class systems with thousands of nodes.
Distributed file content and metadata
One of the most fundamental advantages of BeeGFS is the strict avoidance of architectural bottlenecks or locking situations in the cluster, through the user-space architecture. This concept enables non-disruptive and linear scaling at the metadata & storage levels.
HPC technologies
BeeGFS is based on highly efficient and scalable multithreaded core components with native RDMA support. File system nodes can serve RDMA (InfiniBand, (Omni-Path), RoCE, and TCP/IP) network connections simultaneously and automatically switch to a redundant connection path if one fails.
Easy to use
BeeGFS does not require kernel patches (the client is a patchless kernel module, the server components are user-space daemons), it comes with graphical Grafana dashboards, and it allows adding more clients and servers to a production system as needed.
Client and server on any machine
BeeGFS does not require any particular enterprise Linux distribution or other special environment to run. It uses existing partitions formatted with one of the standard Linux file systems, e.g. XFS, ext4 or ZFS, which enables various use cases.
Optimized for highly concurrent access
Simple remote file systems such as NFS not only have severe performance issues with highly concurrent accesses, they can even corrupt data when multiple clients write to the same shared file, which is a typical use case for cluster applications. BeeGFS is specifically designed for such use cases to provide optimal robustness and performance in situations with high I/O loads or patterns.
Robust
High availability design for continuous operation
SCALABILITY
Increase file system performance and capacity, seamlessly and non-disruptively
EASE OF USE
Easy implementation and integration with existing infrastructure
performance
Well balanced from small to large files
BeeGFS is widely regarded as an easy-to-deploy alternative to other parallel file systems and is used at thousands of sites around the globe. It provides fast access to storage systems of all types and sizes in all performance-oriented environments, including but not limited to HPC, AI and Deep Learning, Life sciences, and Oil & Gas.
The BeeGFS userspace architecture is "state of the art", allowing users to manage any IO profile requirements without performance constraints and enabling the scalability & flexibility required to run the most demanding HPC, AI or mission critical applications.
With BeeGFS, customers can invest in scalable HPC and AI infrastructures that range from small sites to large scale-out environments, offloading the full bandwidth of their hardware components. BeeGFS increases productivity by delivering faster results and enabling new data analysis methods without changing workflows or applications.
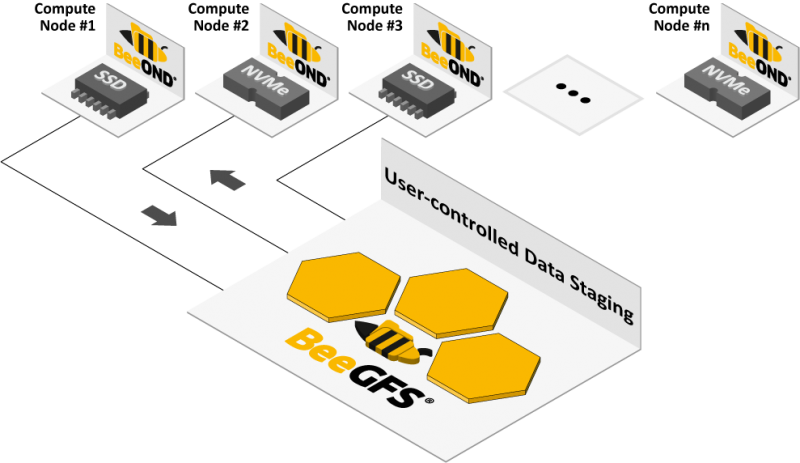
BeeOND is designed to integrate with cluster batch systems to create temporary parallel file system instances on a job-by-job basis on the internal SSDs / NVMe of compute nodes that are part of a compute job.
Such BeeOND instances not only provide a very fast and easy-to-use temporary buffer, but can also keep much of the I/O load for temporary or random access files off the global cluster storage. Increasing the performance of client nodes by adding such functionality greatly accelerates critical projects.
This website uses cookies, which are necessary for the technical operation of the website and are always set. Other cookies, which increase the usability of this website, serve for direct advertising or simplify interaction with other websites and social networks, will only be used with your consent.