ARTIFICIAL INTELLIGENCE IS BOOSTING ALL AREAS OF THE ECONOMY:
DEFINITION: ARTIFICIAL INTELLIGENCE, MACHINE LEARNING, DEEP LEARNING
Artificial intelligence (AI) is a branch of computer science that deals with the development of intelligent machines that work and react like humans. It is the major project for the formation of non-human intelligence. Main components are:
- The main tasks of machine learning (traditional computer vision) are data preparation, feature engineering, model architecture and numerical optimisation. Feature engineering takes up almost 80 per cent of the preparation work.
- Deep learning, a part of machine learning, is a collection of easy-to-train mathematical entities organised in layers that work together to solve complicated tasks. New features include layered network architecture and a scalable training method. DL learns features directly from the data; explicit feature engineering is not required. It has achieved an extremely high level of accuracy, outperforms human performance in classifying images, never tires and delivers results in a fraction of the time.
HOW TO SET UP AN ENTERPRISE DEEP LEARNING / HPC ENVIRONMENT
KI WORKFLOW AND SIZING, IT ALL STARTS WITH THE DATA
A typical AI/Deep Learning development workflow:

THE WORKFLOW IS DESCRIBED AS FOLLOWS:
- Data factory collects raw data and includes tools for pre-processing, indexing, labelling and managing data
- AI models are trained on labelled data using a DL framework from the NVIDIA GPU Cloud (NGC) container repository running on servers with Volta Tensor Core GPUs
- AI model testing and validation adjusts model parameters as needed and repeats training until desired accuracy is achieved
- AI model optimisation for production use (inference) is completed with the NVIDIA TensorRT optimisation inference accelerator
HPC WORKFLOW AND SIZING, IT ALL STARTS WITH THE DATA MODEL
A typical HPC development workflow:
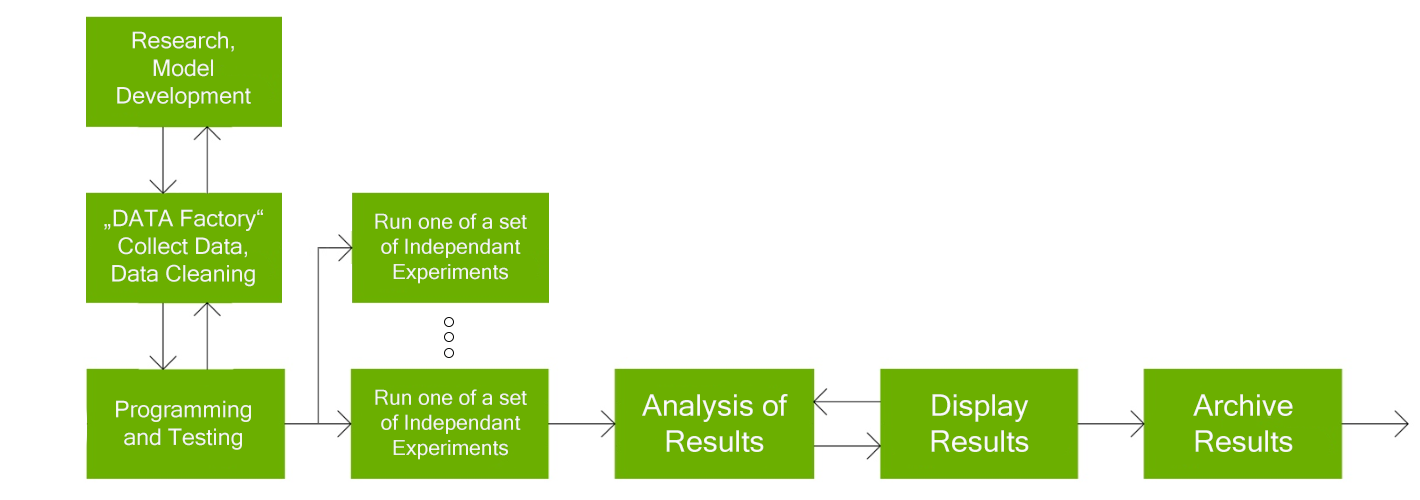
THE WORKFLOW IS DESCRIBED AS FOLLOWS:
- Research and model development
- Data acquisition and cleaning
- Programming and testing
- Run independent experiments
- Visualise, display your results
- Check your results, if you find errors go to step 1, otherwise archive your results
WHAT ARE THE BUILDING BLOCKS OF AN ENTERPRISE DEEP LEARNING / HPC ENVIRONMENT?
Following the workflow, we need the following system modules:
- Storage-Systems
- Storage that is equally well suited for Deep Learning and HPC.
- Since supercomputing is write-intensive and sequential in access, and AI is read-intensive and random in access, the storage systems we offer are designed to best support both HPC and AI. This way you avoid duplicate investments in hardware, storage software and training.
- Storage that is easily expandable on the fly by adding additional servers or JBODs (HDD) or JBOFs (NVMe/SAS/SATA SSD).
- Storage that supports fast operational data, archived data and ultra-fast data stores temporarily mounted on the local NVMe SSDs of converged computing and storage servers.
- Fault-tolerant storage that compensates for the loss of data, complete HDD or SSD, or complete servers including all data on their RAID volumes - all with commodity servers and shared-nothing hardware.
- For more information, see the storage section of this paper or our web offering.
- GPU-Components-Server
- GPU computing equally well suited for Deep Learning and HPC.
Since DL models often require an extremely large amount of memory, it is very important that GPU cards have as much local memory as possible. Current V100 GPU cards therefore have 32 GB of HBM2 memory. - HPC is extremely computationally intensive and requires state-of-the-art GPUs. HPC is extremely computationally intensive and requires state-of-the-art GPUs. The Tensor cores of the V100 can also be used for HPC applications.
- For more information, see the GPU Computing part of this paper or our website.
- GPU computing equally well suited for Deep Learning and HPC.
- Cluster-Network
- Deploy the most cost-effective networking solutions with the most advanced interconnect technology.
The network connects everything together and enables communication between all servers, administrators and developers, making the components one system. - Today's DL/HPC applications rely heavily on high-bandwidth, low-latency connections. In most cases, cluster fabrics are equipped with 40/100 Gbps FDR/EDR InfiniBand or 40/100 Gbps Ethernet.
- For more information, see the GPU computing section of this paper or our web site.
- Deploy the most cost-effective networking solutions with the most advanced interconnect technology.
- Cluster-Management software
- Cluster management software extends your data centre and unleashes the unlimited power of the cloud.
- HPC is extremely computationally intensive and requires state-of-the-art GPUs. HPC is extremely compute-intensive and requires state-of-the-art graphics processors. The V100's tensor cores can also be used for HPC applications.
- Optimised software stack for GPU servers
- NVIDIA uses an optimised software stack for the entire family.
- For non-DGX servers with V100 GPUs, a similar software stack is provided by sysGen.
- For more information, see the Software Management tab on this page.
- Available Deep Learning Solutions and Frameworks
- There are already several viable solutions available, such as DIGITS from NVIDIA.
- For own applications, many different frameworks for different programming languages (C, C++, Python, Java, Scala, Matlab) are available such as Tensor Flow, Caffe, PyTorch, Theano and Deeplearning4y.
- Further information can be found on the internet.
SYSGEN GPU-SERVER, BENEFIT FROM 20 YEARS OF HPC EXPERIENCE IN CLOSE CONNECTION WITH LEADING TECHNOLOGY PROVIDERS- YOU NEVER GO ALONE
GPU-ACCELERATED SERVERS FOR HPC/DL WORKLOADS
WHAT YOU NEED TO PAY ATTENTION TO
Since DL models often require an extremely large amount of memory, it is very important that the GPU cards have as much local memory as possible. Therefore, current V100 GPU cards have 32 GB of HBM2 memory.
In the vast majority of cases, model calculations are distributed across 4 to 16 GPU cards. Frequent retrieval of new data from the mass memory slows down corresponding calculations considerably. In many cases, the individual GPU cards can therefore exchange data directly with each other. If the data exchange takes place via the PCIe bus, the calculation slows down to a lesser extent. It is important that all GPU cards are connected via a single CPU. This is called a single-root complex. Up to 10 GPU cards can be connected via single root, but a sensible number is 8 GPU cards. Direct NVLink connections between GPU cards offer a strong improvement compared to a PCIe connection. A single NVIDIA Tesla® V100 GPU supports up to six NVLink connections and a total bandwidth of 300 GB/s - 10 times the bandwidth of PCIe Gen 3.
SYSTEMS WITH THE HIGHEST PERFORMANCE AND POWER DENSITY:

STORAGE FOR HPC/DL WORKLOADS, HIGHEST PERFORMANCE, RELIABILITY, FAULT TOLERANCE AND
EASY EXPANDABILITY
WHY USE PURE STORAGE FLASHBLADE?
Pure Storage FlashBlade is an extremely high-performance, highly secure scale-out architecture for unstructured data.
Up to 2x faster than previous generation AFAs and with up to 3PB effective in 6U, //X90 provides maximum acceleration and consolidation for all your workloads. It's your enterprise-in-a-box
Take a look at what Pure Storage can do for you:
- Elastic performance that grows with your data - up to 17 GB/s.
- Always fast, from small, metadata-heavy workloads to large streaming files
- All-flash performance without caching or tiering
- Petabytes of capacity
- 10s of billions of objects and files
- "Tuned for Everything" design, no manual optimisations required
- Scale everything instantly by simply adding blades
WHY USE BEEGFS?
BeeGFS transparently distributes user data across multiple servers. By increasing the number of servers and disks in the system, you can easily scale the performance and capacity of the file system to the level you need, seamlessly from small clusters to enterprise-class systems with thousands of nodes.
Take a look at what BeeGFS can do for you:
- Reduce the time it takes to get visibility into your data and information on-premise and in the cloud.
- Cluster storage systems for high performance computing (HPC) and deep learning (DL).
- Modern clustered storage must handle workloads for HPC and DL equally well
- HPC computing is write-intensive and sequential - AI is more read-intensive and randomised
- sysGen storage systems are designed to support both HPC and AI with maximum performance
- BeeGFS runs on various platforms, such as X86, OpenPower, ARM and more
SOFTWARE MANAGEMENT
System developers often underestimate the installation and maintenance effort required for complex software systems. Time lost until a system is ready for use and performance losses due to poor tuning cause high costs and can also delay the introduction of new products. Often, the maintenance effort required to adapt to rapidly evolving software innovations is also greatly underestimated. That is why we deliver our systems and clusters with pre-installed software on request. In this way, our HPC and DL systems or clusters can be used directly.
For all systems with TESLA GPU cards, we install the NVIDIA GPU Cloud software free of charge. For NVIDIA DGX systems, we offer NVIDIA support contracts for one, two or three years. For all other systems, we offer a sysGen update service for the NVIDIA GPU Cloud Software. However, you can also carry out the updates yourself.
NVIDIA'S OPTIMISED SOFTWARE STACK FOR THE ENTIRE DGX FAMILY
One software stack for the whole family:
- A single, unified stack for deep learning frameworks.
- Predictable execution on all platforms.
- The protocol of choice for next-generation storage technologies
- End-to-end coverage Support for RDMA over Converged Ethernet (ROCE)
CLUSTER SYSTEMS FOR HPC AND DEEP LEARNING
We offer the following solutions for HPC and DL cluster systems for parallel multi-user operation:
- sysGen Open Source HPC Cluster
- Bright Enterprise HPC and DL Cluster Manager (see below)
BRIGHT CLUSTER MANAGER EXPANDS YOUR DATA CENTRE AND UNLEASHES THE UNLIMITED POWER OF THE CLOUD
SYSGEN SUPPORTS HIGH PERFORMANCE CLUSTERS FOR ALMOST ALL TYPES OF PROBLEMS:
- HPC clusters for scientific solutions
- HPC clusters for deep learning solutions
- Clusters for Big Data solutions
- Clusters for Clouds
- Clusters that do it all in one
OUR COMPREHENSIVE CLUSTER PHILOSOPHY
Our software automates the process of creating and managing Linux clusters in your data centre and in the cloud:
- Rapid provisioning of computing capacity
- Deploy 10 to 10,000+ nodes of bare metal in minutes
- Rededication of servers to adapt to fluctuating workloads during operation
- Dynamically extend your on-premises environment to AWS and Azure
- Automate deployment, implementation and management
MORE INFORMATION:
Deep learning and high-performance computing are converging, and the required infrastructure and cluster software are almost identical for both applications. Take a look at our solutions pages and get an idea of the extreme performance of the Tesla V100 solutions.
You should pay special attention to the DGX-2, the world-s most powerful HPC/DL server. The DGX-s has 16 V100 cards connected bidirectionally via 12 NVSwitches at 2.4 TB/s and operates like a single virtual GPU with 512 GB of memory. Thus, complex tasks are solved at a fraction of the previous computing time.