THE WORLD'S PROVEN CHOICE FOR CORPORATE SKI
The cornerstone of your AI competence center
DGX H100 is the fourth generation of the world's first purpose-built AI infrastructure: a fully optimized hardware and software platform that includes support for NVIDIA's new AI software solutions, an extensive ecosystem of third-party support, and access to expert consulting from NVIDIA professional services.
Boundless scalability with AI
NVIDIA DGX H100 delivers 6x faster performance, 2x faster networking, and high-speed scalability for NVIDIA DGX SuperPOD. The next-generation architecture is optimized for massive workloads such as natural language processing and deep learning recommendation models.
NVIDIA DGX H100
The latest iteration of NVIDIA DGX systems, providing a highly systemized and scalable platform to solve the biggest challenges using AI.
The DGX H100 is an AI powerhouse equipped with the breakthrough NVIDIA H100 Tensor Core GPU. Designed to maximize AI throughput, the system provides enterprises as well as research institutions with a sophisticated, systematized and scalable platform that helps achieve breakthroughs in, for example, natural language processing, recommendation systems, data analytics and much more. Available on-premise and through a variety of access and deployment options, the DGX H100 delivers the power enterprises need to solve their biggest challenges with AI.

DETAILS
8x NVIDIA H100 GPUs WITH 640 GIGABYTE TOTAL GPU MEMORY
18x NVIDIA® NVLinks® per GPU, 900 gigabytes per second of bi-directional bandwidth between GPUs
4x NVIDIA NVSWITCHES™
7.2 terabytes per second of bidirectional bandwidth for interconnects between GPUs - 1.5 times more than the previous generation
8x NVIDIA CONNECTX®-7 and 2x NVIDIA BLUEFIELD® DPU NETWORK INTERFACE WITH 400 GBIT/SEK.
Peak 1 terabyte per second bidirectional network bandwidth
DUAL x86 CPUS AND 2 TERABYTE SYSTEM MEMORIES
Powerful CPUs for the most intensive AI tasks
30 TERABYTE NVME SSD
High-speed data storage for maximum performance

Comparison DGX H100 vs. DGX A100
Specifications
COMPONENTS | NVIDIA DGX H100 | NVIDIA DGX A100 |
|---|---|---|
GPU | 8x NVIDIA H100 Tensor Core GPUs | 8x NVIDIA A100 80GB Tensor Core GPUs |
GPU memory | 640GB total | 640GB total |
Performance | 32 petaFLOPS FP8 | 5 petaFLOPS AI 10 petaOPS INT8 |
NVIDIA® NVSwitch™ | 4x | 6 |
System power usage | ~10.2kW max | 6.5 kW max |
CPU | Dual x86 | Dual AMD Rome 7742, 128 cores total, 2.25 GHz (base), 3.4 GHz (max boost) |
System memory | 2TB | 2TB |
Networking | 4x OSFP ports serving 8x single-port NVIDIA ConnectX-7 400Gb/s InfiniBand/Ethernet 2x dual-port NVIDIA BlueField-3 DPUs VPI 1x 400Gb/s InfiniBand/Ethernet 1x 200Gb/s InfiniBand/Ethernet | 8x SinglePort NVIDIA ConnectX-7 200Gb/s InfiniBand 2x Dual-Port NVIDIA ConnectX-7 VPI 10/25/50/100/200 Gb/s Ethernet |
Management network | 10Gb/s onboard NIC with RJ45 50Gb/s Ethernet optional NIC Host baseboard management controller (BMC) with RJ45 2x NVIDIA BlueField-3 DPU BMC (with RJ45 each) | - |
Storage | OS: 2x 1.9TB NVMe M.2 Internal storage: 8x 3.84TB NVMe U.2 | OS: 2x 1.92TB M.2 NVME drives Internal Storage: 30TB (8x 3.84 TB) U.2 NVMe drives |
System software | DGX H100 systems come preinstalled with DGX OS, which is based on Ubuntu Linux and includes the DGX software stack (all necessary packages and drivers optimized for DGX). Optionally, customers can install Ubuntu Linux or Red Hat Enterprise Linux and the required DGX software stack separately. | Ubuntu Linux OS Also supports: Red Hat Enterprise Linux CentOS |
Operating temperature range | 5 to 30°C (41-86°F) | 5 to 30°C (41-86°F) |
NVIDIA H100 TENSOR CORE GPU
Unprecedented performance, scalability and security for any data center

Securely accelerate workloads from enterprise to exascale
Securely accelerate workloads from enterprise to exascale
Up to 9 times faster AI training for the largest models
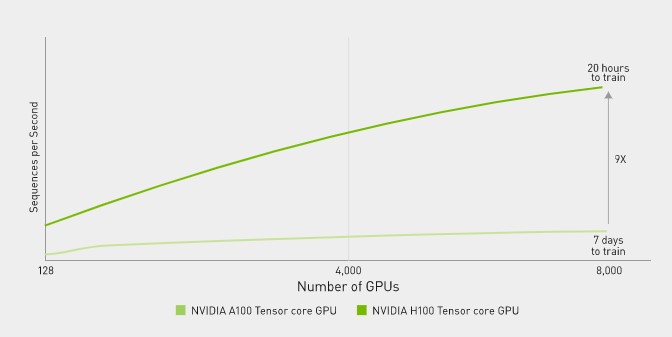
Transformational AI Training
Transformational AI Training
NVIDIA H100 GPUs feature fourth-generation Tensor compute units and the Transformer Engine with FP8 precision, which provides up to 9x faster training compared to the previous generation for Mixture of Experts (MoE) models. The combination of fourth-generation NVlink, which provides 900 gigabytes per second (GB/s) GPU-to-GPU connectivity; NVSwitch, which accelerates collective communication through each GPU across nodes; 5th-generation PCIe; and NVIDIA Magnum IO™ software provides efficient scalability from small enterprises to massive, unified GPU clusters.
Deploying H100 GPUs at data center scale delivers unprecedented performance and the next generation of exascale high-performance computing (HPC) and trillion-parameter AI for all researchers.
Real-Time Deep Learning Inference
Real-Time Deep Learning Inference
AI solves a wide range of business challenges with an equally wide range of neural networks. A superior AI inference accelerator must provide not only the highest performance, but also the versatility to accelerate these networks.
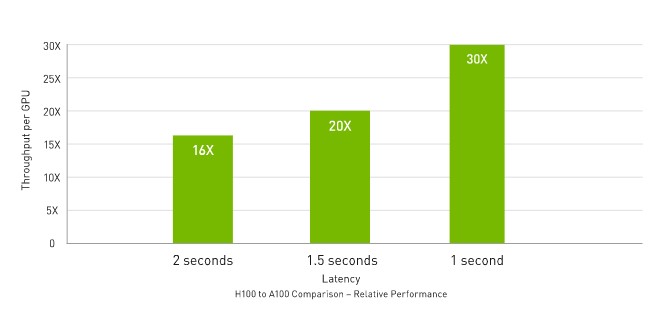
H100 further extends NVIDIA's market-leading position in inference with several advances that accelerate inference by up to 30x and provide the lowest latency. Fourth-generation Tensor compute units accelerate all precisions, including FP64, TF32, FP32, FP16, as well as INT8, and the Transformer Engine uses FP8 and FP16 together to reduce memory usage and increase performance while maintaining accuracy for large language models.
Up to 30 times higher AI inference performance for the largest models
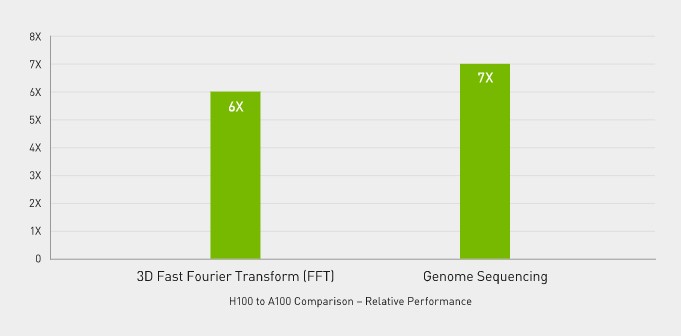
Up to 7 times higher performance for HPC applications
Exascale High-Performance Computing
Exascale High-Performance Computing
The NVIDIA data center platform consistently delivers performance gains that go beyond Moore's Law. H100's new breakthrough AI capabilities further amplify the power of HPC + AI to accelerate time to discovery for scientists and researchers working to solve the world's most important challenges.
H100 triples the floating-point operations per second (FLOPS) of Tensor Cores with twice the accuracy, delivering 60 teraFLOPS of FP64 computing for HPC. AI-powered HPC applications can leverage H100's TF32 precision to achieve petaFLOPS throughput for single-precision matrix multiplication operations, without code changes.
H100 also features DPX instructions, which provide 7x performance over NVIDIA A100 Tensor Core GPUs for dynamic programming algorithms such as Smith-Waterman for DNA sequence alignment, and 40x acceleration over traditional servers with dual-socket CPUs alone.
Technical data
Form factor | H100 SXM | H100 PCIe |
|---|---|---|
FP64 | 30 teraFLOPS | 24 teraFLOPS |
FP64 tensor core | 60 teraFLOPS | 48 teraFLOPS |
FP32 | 60 teraFLOPS | 48 teraFLOPS |
TF32 Tensor Core | 1.000 teraFLOPS* | 500 teraFLOPS | 800 teraFLOPS* | 400 teraFLOPS |
BFLOAT16 tensor core | 1.000 teraFLOPS* | 500 teraFLOPS | 1.600 teraFLOPS* | 800 teraFLOPS |
FP16 tensor core | 2.000 teraFLOPS* | 1,000 teraFLOPS | 1.600 teraFLOPS* | 800 teraFLOPS |
FP8 Tensor Core | 4.000 teraFLOPS* | 2,000 teraFLOPS | 3.200 teraFLOPS* | 1,600 teraFLOPS |
INT8 tensor core | 4.000 TOPS* | 2,000 TOPS | 3.200 TOPS* | 1,600 TOPS |
GPU memory | 80 GB | 80 GB |
GPU memory bandwidth | 3TB/s | 2TB/s |
Decoders | 7 NVDEC / 7 JPEG | 7 NVDEC / 7 JPEG |
Max thermal design power (TDP) | 700W | 350W |
Multi-Instance GPUs | Up to 7 MIGS @ 10GB each | Up to 7 MIGS @ 10GB each |
Form factor | SXM | PCIe |
Interconnect | NVLink: 900GB/s PCIe Gen5: 128GB/s | NVLINK: 600GB/s PCIe Gen5: 128GB/s |
Server options | NVIDIA HGX™ H100 Partner and NVIDIA-Certified Systems™ with 4 or 8 GPUs NVIDIA DGX™ H100 with 8 GPUs | Partner and NVIDIA-Certified Systems with 1-8 GPUs |
Designed for enterprise AI
Designed for enterprise AI
The NVIDIA DGX SuperPOD provides a ready-to-go AI data center solution for enterprises that want to focus on insights rather than infrastructure, with world-class computing, software tools, expertise and continuous innovation seamlessly delivered.
Offered with two options for compute infrastructure, DGX SuperPOD enables any enterprise to integrate AI across all business units and develop breakthrough applications,
rather than wrestle with platform complexity.
DGX SuperPOD with NVIDIA DGX H100 systems
DGX SuperPOD with NVIDIA DGX H100 systems
AI workloads, such as large language models with NVIDIA
NeMo and Deep Learning recommendation systems.
Break through barriers with the
DGX H100 SuperPOD
DGX H100 SuperPOD
NVIDIA will be the first to build a DGX SuperPOD with the groundbreaking new DGX H100 AI architecture to support the work of NVIDIA researchers advancing climate science, digital biology and the future of AI.
the latest DGX SuperPOD architecture features a new NVIDIA NVLink switch system that can connect up to 32 nodes with a total of 256 H100 GPUs.
The next-generation DGX SuperPOD delivers 1 exaflops of FP8 AI performance, 6x more than its predecessor, and pushes the boundaries of AI with the ability to run massive LLM workloads with trillions of parameters.

CONVERGED ACCELERATOR H100 CNX FROM NVIDIA
Converged accelerator H100 CNX
from NVIDIA
Converged accelerator H100 CNX
from NVIDIA
NVIDIA H100 CNX combines the performance of the NVIDIA H100 with the advanced networking capabilities of the NVIDIA ConnectX®-7 Smart Network Interface Card (SmartNIC) in a single, unique platform. This convergence delivers unprecedented performance for GPU-based input/output (IO)-intensive workloads, such as distributed AI training in the enterprise data center and 5G processing at the edge.
BETTER I/O PERFORMANCE
BALANCED, OPTIMIZED DESIGN
COST SAVINGS
READY FOR USE
H100 CNX - Technical data
H100 CNX - Technical data
Technical data | |
|---|---|
GPU memory | 80 GB HBM2e |
Memory bandwidth | > 2.0 Tb/s |
MIG instances | 7 instances with 10 GB each 3 instances with 20 GB each 2 instances with 40 GB each |
Connectivity | PCIe Gen5 128 GB/s |
NVLINK bridge | 2-way |
Network | 1x 400 Gb/s, 2x 200 Gb/s ports, Ethernet or InfiniBand |
Form factor | FHFL Dual Slot (Full Height, Full Length) |
Max. Power | 350 W |
NVIDIA Spectrum SN4000 Open

Ethernet SWiTCHE
is driving performance volumes across all industries.
NVIDIA switches provide wide bandwidth for data access and communications in the data center.
NVIDIA GRACE-CPU
NVIDIA GRACE-CPU