Game-changing performance: NVIDIA A100 Tensor Core GPU
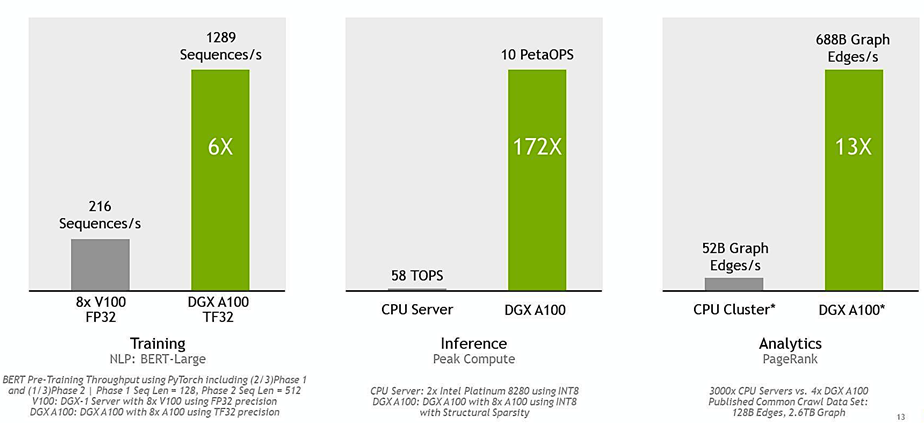
Game-changing performance based on the NVIDIA A100 GPU, delivering the world's first 5 PFLOPS AI system that can effortlessly run analysis, training, and inference workloads simultaneously.
The NVIDIA DGX A100 features eight NVIDIA A100 Tensor Core GPUs, providing users with unmatched acceleration, and is fully optimized for NVIDIA CUDA-X™ software and the end-to-end NVIDIA Data Center Solution Stack.
NVIDIA A100 GPUs offer a new precision, TF32, that works like FP32 to deliver a 20X increase in FLOPS performance for AI compared to the previous generation - and best of all, no code changes are required to achieve this speed increase. And when using NVIDIA's automatic mixed-precision, the A100 provides an additional 2x performance boost with just one additional line of code at FP16 precision. The A100 GPU also features class-leading memory bandwidth of 1.6 terabytes per second (TB/s), an increase of more than 70% over the last generation. In addition, the A100 GPU has significantly more on-chip memory, including a 40 MB Level 2 cache that is nearly 7 times larger than the previous generation, maximizing compute performance. The DGX A100 also introduces next-generation NVIDIA NVLink™, which doubles direct GPU-to-GPU bandwidth to 600 gigabytes per second (GB/s), nearly 10X higher than PCIe Gen 4, and a new NVIDIA NVSwitch that is 2X faster than the last generation.
This unprecedented performance delivers the fastest time-to-solution for training, inference, and analytics workloads, enabling users to address challenges that were not possible or practical before.
Unmatched Flexibility: New Multi Instance GPU (MIG) Innovation
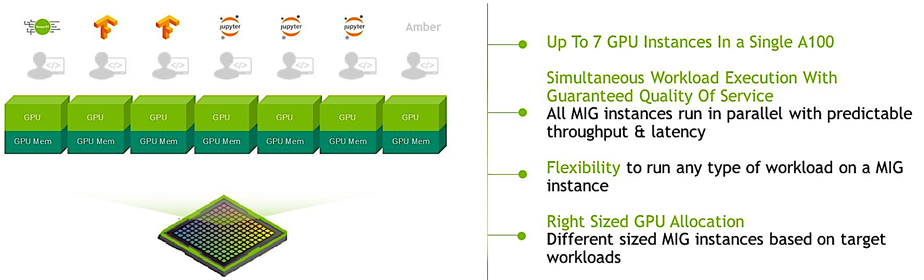
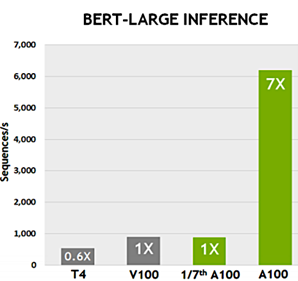
Unmatched flexibility with Multi-Instance GPU (MIG) innovation that enables 7x inference performance per GPU and the ability to allocate resources that are right-sized for specific workloads.
MIG partitions a single NVIDIA A100 GPU into up to seven independent GPU instances. These run concurrently, each with its own memory, cache, and streaming multiprocessors. This allows the A100 GPU to provide guaranteed quality-of-service (QoS) at up to 7x higher utilization compared to previous GPUs.
MIG partitions a single NVIDIA A100 GPU into up to seven independent GPU instances. These run concurrently, each with its own memory, cache, and streaming multiprocessors. This allows the A100 GPU to provide guaranteed quality-of-service (QoS) at up to 7x higher utilization compared to previous GPUs.
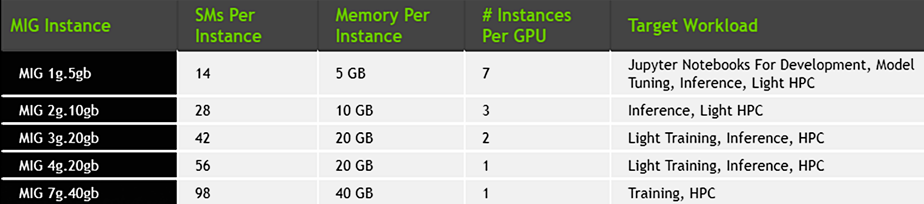
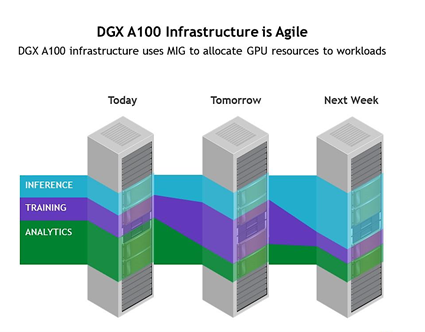
With the DGX A100, you can use up to 56 MIG slices to solve problems with inflexible infrastructures and accurately allocate compute power to each workload. You no longer have to struggle to divide time on a box among multiple competing projects. With MIG on DGX A100, you have enough compute power to support your entire data science team.
Low total cost of ownership: Universal AI platform
Unparalleled TCO/ROI metrics with all the performance of a modern AI data center at 1/10 the cost, 1/25 the space, and 1/20 the performance
Today's AI data center
- 25 Rack for training & inference
- 630 kW
- $11M
DGX A100 Data Center
- 1 rack (5 x DGX A100s)
- 28 kW
- $1M
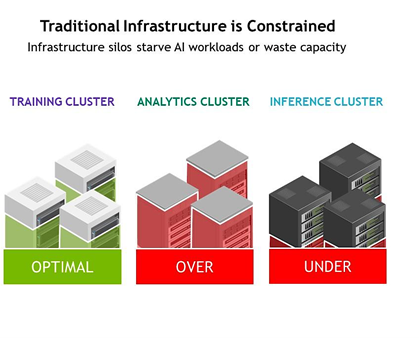
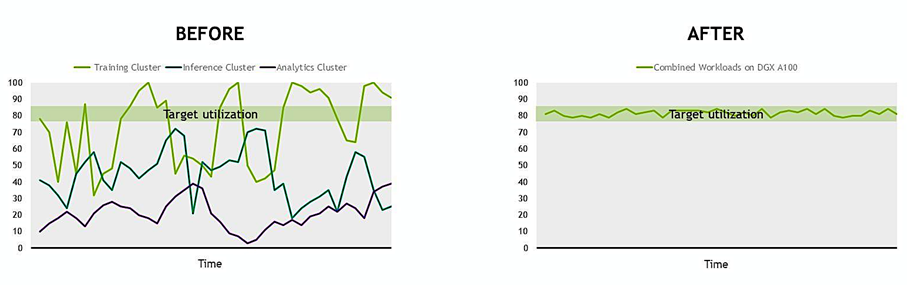
Traditional AI infrastructures typically consist of three separate specialized clusters: training (GPU-based), inference (often CPU-based), and analysis (CPU-based). These inflexible infrastructure silos were never designed for the pace of AI. Most data centers dealing with AI workloads will likely find that these resources are either over- or under-utilized at any given time. The DGX A100 data center with MIG provides you with a single system that can flexibly adapt to your workload requirements.
In many data centers, the demand for computing resources rises and falls, resulting in servers that are mostly underutilized. IT ends up having to buy excess capacity to protect against occasional spikes. With the DGX A100, you can now right-size resources for each job and increase utilization, which lowers TCO.
With DGX A100 data centers, you can easily adapt to changing business needs by deploying a single elastic infrastructure that is much more efficient.