ACCELERATING THE MOST IMPORTANT WORK OF OUR TIME
The NVIDIA A100 Tensor Core GPU delivers unprecedented acceleration at any scale for the world's highest-performing elastic data centers in AI, data analytics, and HPC. A100 is based on the NVIDIA Ampere architecture and is the core component of NVIDIA's data center platform. A100 delivers up to 20 times the performance of the previous generation and can be partitioned into seven GPU instances to dynamically adapt to changing requirements. For the first time, A100 80 GB uses the world's highest memory bandwidth of over 2 terabytes per second (TB/s) to handle the largest models and datasets.
ENTERPRISE-READY SOFTWARE FOR KI

THE MOST POWERFUL END-TO-END DATA CENTER PLATFORM
FOR KI AND HPC
FOR KI AND HPC
A100 is part of NVIDIA's complete data center solution, which includes building blocks for NGC™ hardware, networking, software, libraries, and optimized AI models and applications. It represents the most powerful end-to-end AI and HPC platform for data centers, enabling researchers to deliver realistic results and deploy solutions at scale.
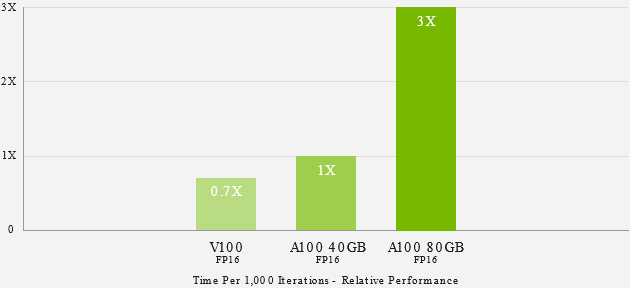
UP TO 3 TIMES FASTER KI TRAINING WITH THE LARGEST MODELS
DEEP LEARNING TRAINING
The complexity of AI models is increasing rapidly to meet new challenges such as conversational AI. Training them requires tremendous computational power and scalability.
NVIDIA A100's tensor compute units with Tensor Float(TF32) precision provide up to 20x more performance over NVIDIA Volta, requiring no code changes to do so and providing an additional 2x boost with automatic mixed precision and FP16. When combined with NVIDIA® NVLink®, NVIDIA NVSwitch™, PCI Gen4, NVIDIA® Mellanox® InfiniBand®, and the NVIDIA Magnum IO™ SDK, scaling to thousands of A100 GPUs is possible.
Training workloads like BERT can be solved at scale with 2,048 A100 GPUs in under a minute, setting a world record for solution time.
For the largest models with massive data tables such as deep learning recommendation models (DLRMs), the A100 80 GB achieves up to 1.3 TB of unified memory per node and provides up to 3 times more throughput than the A100 40 GB.
NVIDIA's leadership in MLPerf has been solidified by multiple performance records in AI training benchmarks across the industry.
INFERENCE FOR DEEP LEARNING
uP TO 249 TIMES HIGHER PERFORMANCE WITH KI INFERENCE
COMPARED TO
COMPARED TO
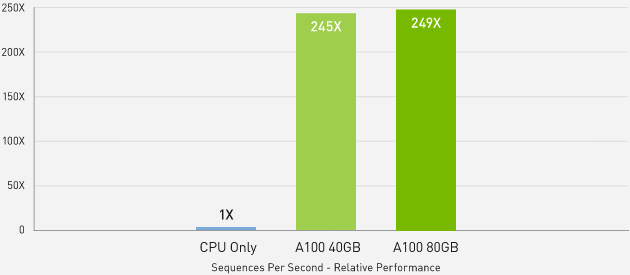
BERT-Large Inference | CPU only: Xeon Gold 6240 @ 2.60 GHz, precision = FP32, batch size = 128 | V100: NVIDIA TensorRT (TRT) 7.2, precision =™ INT8, batch size = 256 | A100 40GB and 80GB, batch size = 256, precision = INT8 with sparsity.
UP TO 1.25 TIMES HIGHER PERFORMANCE WITH KI INFERENCE
COMPARED TO A100 40 GB
COMPARED TO A100 40 GB
MLPerf 0.7 RNN-T measured with (1/7) MIG slices. Framework: TensorRT 7.2, dataset = LibriSpeech, precision = FP16.
HIGH-PERFORMANCE COMPUTING
Scientists use simulations with NVIDIA A100 to make discoveries accessible and understand the world. A100 introduces double precision tensor compute units and 80GB of the fastest graphics memory. This reduces simulations to less than four hours and provides 11x throughput on dense matrix multiplication tasks. With additional memory and unmatched bandwidth, the A100 80 GB is ideal for next-generation workloads.Learn more about the A100 for HPC
11 times more HPC performance in four years
Leading HPC applications
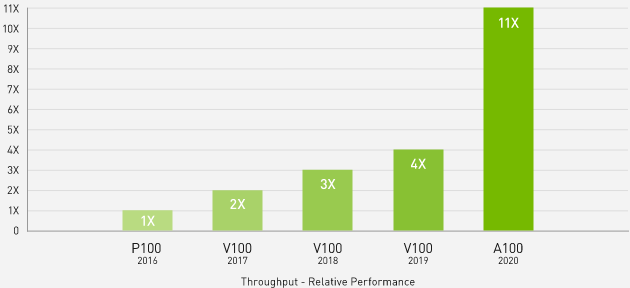
Geometric mean of application acceleration vs. P100: benchmark application: Amber [PME-Cellulose_NVE], Chroma [szscl21_24_128], GROMACS [ADH Dodec], MILC [Apex Medium], NAMD [stmv_nve_cuda], PyTorch (BERT Fast Fine Tuning], Quantum Espresso [AUSURF112-jR]; Random Forest FP32 [make_blobs (160000 x 64:10)], TensorFlow [ResNet-50], VASP 6 [Si Huge] | GPU nodes with dual-socket CPUs with 4x NVIDIA P100, V100 or A100 GPUs.
Up to 1.8 times higher performance for HPC applications
Quantum espresso
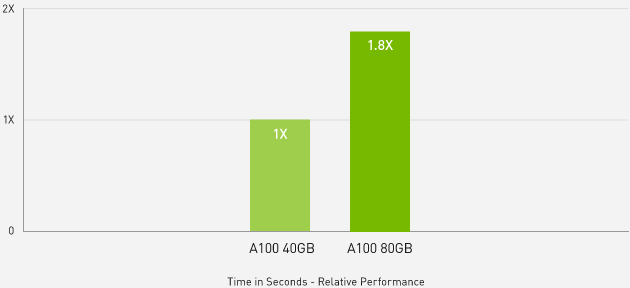
Quantum Espresso measured using CNT10POR8 dataset, precision = FP64.
POWERFUL DATA ANALYSIS
Data scientists need to analyze, visualize, and gain insights from data. Horizontal scaling solutions often don't work because data is spread across multiple servers. NVIDIA's A100 servers accelerate workloads with compute power, massive memory, 2TB/s storage bandwidth, and scalability. Together with InfiniBand, NVIDIA Magnum IO and RAPIDS suite, NVIDIA's data center platform accelerates massive workloads with unmatched performance and efficiency. The A100 delivers insights in a Big Data benchmark with 83x higher throughput and 2x higher performance than A100 40GB and is ideal for new workloads with immense data sets.
Learn more about data analytics
Up to 83x faster than CPU, 2x faster than A100 40 GB in Big Data analytics benchmark
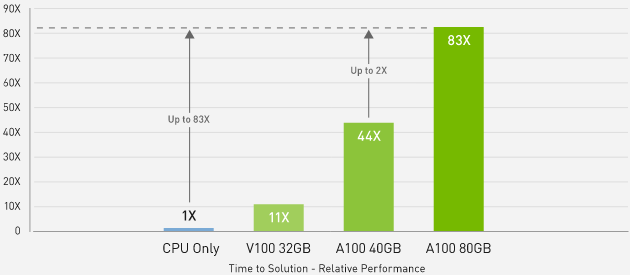
Big Data analytics benchmark | 30 analytics trade queries, ETL, ML, NLP on 10 TB dataset | CPU: Intel Xeon Gold 6252 2.10 GHz, Hadoop | V100 32 GB, RAPIDS/Dask | A100 40 GB and A100 80 GB, RAPIDS/Dask/BlazingSQL
2X faster than A100 40GB in Big Data Analytics benchmark
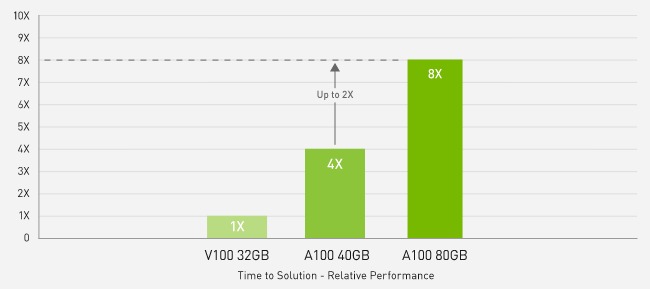
Big data analytics benchmark | 30 analytical retail queries, ETL, ML, NLP on 10TB dataset | V100 32GB, RAPIDS/Dask | A100 40GB and A100 80GB, RAPIDS/Dask/BlazingSQL
COMPETITIVE WORKLOAD
7 TIMES HIGHER INFERENCE THROUGHPUT WITH MULTI-INSTANCE GRAPHICS PROCESSOR (MIG)
BERT Large Inference
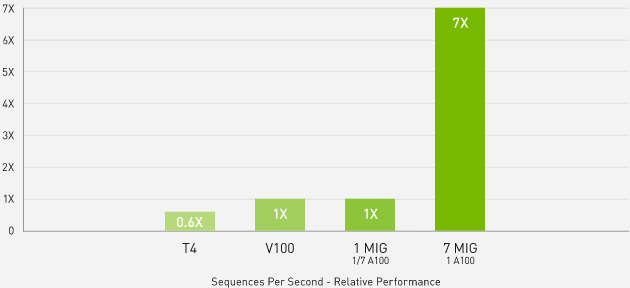
BERT Large Inference | NVIDIA TensorRT™ (TRT) 7.1 | NVIDIA T4 Tensor Core GPU: TRT 7.1, precision = INT8, batch size = 256 | V100: TRT 7.1, precision = FP16, batch size = 256 | A100 with 1 or 7 MIG instances of 1g.5gb: batch size = 94, precision = INT8 with sparsity.
A100 with MIG optimizes the utilization of GPU-accelerated infrastructure. With MIG, an A100 GPU can be partitioned into up to seven independent instances, allowing multiple users to benefit from GPU acceleration simultaneously. On the A100 40 GB, each MIG instance can be allocated up to 5 GB, and the increased memory capacity doubles this to 10 GB on the A100 80 GB.
MIG works with Kubernetes, containers and hypervisor-based server virtualization. MIG enables infrastructure management to assign a customized GPU to each task with guaranteed quality of service (QoS), giving every user access to accelerated computing resources.
Learn more about MIG
Transform your AI workloads with the NVIDIA DGX A100

GPUS FOR DATA CENTERS

NVIDIA A100 FOR HGX

NVIDIA A100 FOR PCIE
TECHNICAL DATA
A100 80 GB PCIe | A100 80 GB SXM | |
|---|---|---|
FP64 | 9.7 TFLOPS | 9.7 TFLOPS |
FP64 tensor core | 19.5 TFLOPS | 19.5 TFLOPS |
FP32 | 19.5 TFLOPS | 19.5 TFLOPS |
Tensor Float 32 (TF32) | 156 TFLOPS | 312 TFLOPS* | 156 TFLOPS | 312 TFLOPS* |
BFLOAT16 tensor computing unit | 312 TFLOPS | 624 TFLOPS* | 312 TFLOPS | 624 TFLOPS* |
FP16 tensor computing unit | 312 TFLOPS | 624 TFLOPS* | 312 TFLOPS | 624 TFLOPS* |
INT8 tensor computing unit | 624 TOPS | 1248 TOPS* | 624 TOPS | 1248 TOPS* |
GPU memory | 80 GB HBM2e | 80 GB HBM2e |
GPU memory bandwidth | 1.935 GB/s | 2.039 GB/s |
Max. Thermal Design Power (TDP) | 300 W | 400 W *** |
Multi-instance GPU | Up to 7 MIGs with 10 GB | Up to 7 MIGs with 10 GB |
Form factor | PCIe - two slots with air cooling or one slot with liquid cooling | SXM |
Interconnection | NVIDIA® NVLink® bridge for 2 GPUs: 600 GB/s ** PCIe Gen4: 64 GB/s | NVLink: 600 GB/s PCIe Gen4: 64 GB/s |
Server options | NVIDIA-Certified Systems™ with 1-8 GPUs | NVIDIA HGX™ A100 partners and NVIDIA certified systems with 4, 8 or 16 GPUs NVIDIA DGX™ A100 with 8 GPUs |
** SXM4 GPUs via HGX A100 server boards, PCIe GPUs via NVLink bridge for up to two GPUs
*** 400 W TDP for standard configuration. SKU for HGX A100-80 GB Custom Thermal Solution (CTS) can support TDPs up to 500 W