Diese Website benutzt Cookies, die für den technischen Betrieb der Website erforderlich sind und stets gesetzt werden. Andere Cookies, die den Komfort bei Benutzung dieser Website erhöhen, der Direktwerbung dienen oder die Interaktion mit anderen Websites und sozialen Netzwerken vereinfachen sollen, werden nur mit Ihrer Zustimmung gesetzt.
Konfiguration
Technisch erforderlich
Diese Cookies sind für die Grundfunktionen des Shops notwendig.
"Alle Cookies ablehnen" Cookie
"Alle Cookies annehmen" Cookie
Ausgewählter Shop
CSRF-Token
Cookie-Einstellungen
Individuelle Preise
Kunden-Wiedererkennung
Kundenspezifisches Caching
Session
Währungswechsel
Komfortfunktionen
Diese Cookies werden genutzt um das Einkaufserlebnis noch ansprechender zu gestalten, beispielsweise für die Wiedererkennung des Besuchers.
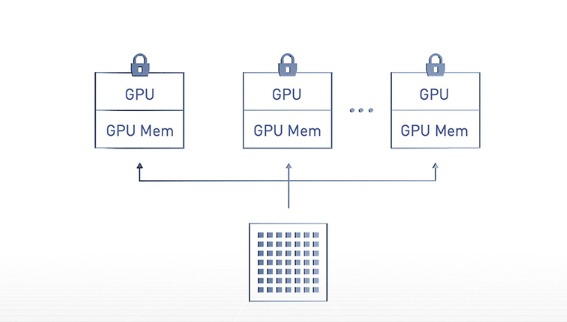
SIEBEN UNABHÄNGIGE INSTANZEN AUF EINER EINZIGEN GPU
Multi-Instance GPU (MIG) erweitert die Leistung und den Wert jedes NVIDIA H100, A100 und A30 Grafikprozessors. MIG kann den A100-Grafikprozessor in bis zu sieben Instanzen partitionieren, die jeweils vollständig isoliert sind und über einen eigenen Speicher mit hoher Bandbreite, Cache und Rechenkerne verfügen. Jetzt können Administratoren jede Arbeitslast unterstützen, von der kleinsten bis zur größten, und für jeden Job eine GPU in der richtigen Größe mit garantierter Servicequalität (QoS) anbieten. Außerdem können dadurch Auslastungen optimiert und die Reichweite der beschleunigten Rechenressourcen auf jeden Benutzer ausgeweitet werden.
LEISTUNGSÜBERSICHT
AUSWEITUNG DES ZUGRIFFS Auf GPUS für MEHRere NUTZER
Mit MIG können Sie bis zu 7x mehr GPU-Ressourcen auf einer einzigen A100-GPU erreichen. MIG bietet Forschern und Entwicklern mehr Ressourcen und Flexibilität als je zuvor.
GPU-AUSLASTUNG OPTIMIEREN
MIG bietet die Flexibilität, viele verschiedene Instanzgrößen auszuwählen, was die Bereitstellung von GPU-Instanzen in der richtigen Größe für jeden Workload ermöglicht, was letztendlich zu einer optimalen Auslastung und Maximierung der Investitionen im Rechenzentrum führt.
MIG ermöglicht die gleichzeitige Ausführung von Inferenz-, Trainings- und High-Performance-Computing (HPC)-Workloads auf einer einzigen GPU mit deterministischen Latenzzeiten und Durchsatz.
WIE DIE TECHNOLOGIE FUNKTIONIERT
Ohne MIG konkurrieren verschiedene Aufgaben, die auf demselben Grafikprozessor ausgeführt werden, z. B. verschiedene KI-Inferenzanfragen, um dieselben Ressourcen wie die Speicherbandbreite. Eine Aufgabe, die eine größere Speicherbandbreite beansprucht, lässt andere verhungern, was dazu führt, dass mehrere Aufgaben ihre Latenzziele verfehlen. Mit MIG werden Aufgaben gleichzeitig auf verschiedenen Instanzen ausgeführt, die jeweils über dedizierte Ressourcen für Rechenleistung, Speicher und Speicherbandbreite verfügen, was zu einer vorhersehbaren Leistung mit hoher Servicequalität und maximaler GPU-Auslastung führt.
Ein NVIDIA A100-Grafikprozessor kann in MIG-Instanzen unterschiedlicher Größe partitioniert werden. So könnte ein Administrator beispielsweise zwei Instanzen mit je 20 Gigabyte (GB) Speicher oder drei Instanzen mit 10 GB oder sieben Instanzen mit 5 GB erstellen. Oder eine Mischung aus beidem. So kann der Systemadministrator den Benutzern für verschiedene Arten von Arbeitslasten GPUs in der richtigen Größe zur Verfügung stellen.
MIG-Instanzen können auch dynamisch rekonfiguriert werden, so dass Administratoren die GPU-Ressourcen entsprechend den sich ändernden Benutzer- und Geschäftsanforderungen verschieben können. So können beispielsweise sieben MIG-Instanzen tagsüber für Inferenzen mit geringem Durchsatz verwendet und nachts zu einer großen MIG-Instanz für Deep-Learning-Training umkonfiguriert werden.
AUSSERGEWÖHNLICHE QUALITÄT DER DIENSTLEISTUNGEN
Jede MIG-Instanz verfügt über einen dedizierten Satz von Hardwareressourcen für Datenverarbeitung, Speicher und Cache, die eine garantierte Servicequalität (QoS) und Fehlerisolierung für die Arbeitslast bieten. Das bedeutet, dass ein Fehler in einer Anwendung, die auf einer Instanz läuft, keine Auswirkungen auf Anwendungen hat, die auf anderen Instanzen laufen. Außerdem können auf verschiedenen Instanzen unterschiedliche Arten von Workloads ausgeführt werden: interaktive Modellentwicklung, Deep Learning-Training, KI-Inferenz oder HPC-Anwendungen. Da die Instanzen parallel ausgeführt werden, laufen auch die Arbeitslasten parallel, jedoch getrennt und isoliert auf derselben physischen A100-GPU.
MIG eignet sich hervorragend für Workloads wie die Entwicklung von KI-Modellen und Inferenzen mit niedriger Latenz. Diese Workloads können die Funktionen der A100 in vollem Umfang nutzen und passen in den jeder Instanz zugewiesenen Speicher.
MIG in NVIDIA H100
Der auf der NVIDIA Hopper™-Architektur basierende H100 erweitert MIG durch die Unterstützung von mandantenfähigen Multi-User-Konfigurationen in virtualisierten Umgebungen für bis zu sieben Grafikprozessorinstanzen, wobei jede Instanz durch Confidential Computing sicher auf Hardware- und Hypervisorebene isoliert ist. Dedizierte Videodecoder für jede MIG-Instanz erlauben intelligente Videoanalysen (IVA) mit hohem Durchsatz auf gemeinsam genutzter Infrastruktur. Mit dem gleichzeitigen MIG-Profiling von Hopper können Administratoren die korrekt dimensionierte Grafikprozessorbeschleunigung überwachen und Ressourcen für mehrere Benutzer zuweisen.
Forscher mit kleineren Workloads können MIG anstelle einer vollständigen Cloud-Instanz verwenden, um einen Teil eines Grafikprozessors sicher zu isolieren, und sich dabei darauf verlassen, dass ihre Daten bei Lagerung, Übertragung und Nutzung geschützt sind. Dadurch wird die Flexibilität für Cloud-Service-Anbieter erhöht, kleinere Kundenpotenziale zu bedienen und preiswerter zu sein.
MIG IN AKTION SEHEN
GEBAUT FÜR IT UND DEVOPS
MIG ermöglicht eine feinkörnige GPU-Bereitstellung durch IT- und DevOps-Teams. Jede MIG-Instanz verhält sich für Anwendungen wie ein eigenständiger Grafikprozessor, so dass keine Änderungen an der CUDA® Plattform vorgenommen werden müssen. MIG kann in allen wichtigen Enterprise-Computing-Umgebungen eingesetzt werden.
7 x 10 GB 4 x 20 GB 2 x 40 GB (mehr Rechenkapazität) 1 x 80 GB
7 x 10 GB 3 x 20 GB 2 x 40 GB 1 x 80 GB
GPU-Profiling und -Überwachung
Gleichzeitig auf allen Instanzen
Nur jeweils eine Instanz
Sichere Mandanten
7x
1x
Mediendekodierer
Dediziertes NVJPEG und NVDEC pro Instanz
Eingeschränkte Optionen
Vorläufige Spezifikationen, Änderungen möglich
Diese Website benutzt Cookies, die für den technischen Betrieb der Website erforderlich sind und stets gesetzt werden. Andere Cookies, die den Komfort bei Benutzung dieser Website erhöhen, der Direktwerbung dienen oder die Interaktion mit anderen Websites und sozialen Netzwerken vereinfachen sollen, werden nur mit Ihrer Zustimmung gesetzt.